本发明属于面向强化学习的防御领域,具体涉及一种面向强化学习的异常数据检测与防御方法。
背景技术:
强化学习是近年来备受关注的人工智能方向之一。其基本思想是通过最大化agent从环境中获得的累积奖励来学习最优策略,从而达到学习目的。但是强化学习的训练过程容易受到攻击,使得训练集数据异常,从而影响了agent在学习过程中的决策或动作选择,最终使agent学习到了失败方向的动作,即对于强化学习非常重要。安全应用的决策领域是一项重大挑战。
目前,根据异常数据结构分布的特点,异常数据的检测和防御方法大致可以分为两类。一种是结构化数据的异常检测方法,其主要思想是通过与正常数据集有较大差异的异常值,将异常值视为异常值。但这种方法一般面临两个问题:一是需要定义清晰的决策边界来定义正常点和异常点;另一个是跨索引计算之间的维度灾难和高频计算性能瓶颈。随着研究的深入,这类异常数据检测主要通过图形位置分布、统计方法检测、距离检测、密度检测和矩阵分解检测来定义正常点和异常点,以达到检测异常数据的目的。二是针对非结构化数据的异常检测防御方法。这种方法常用于图像识别任务。通过对图像对象的检测,识别出异常(故障)点。该方法主要通过数字图像处理、rcnn、yolo等以及ssd物体检测算法实现。
随着强化学习的快速发展和应用防御性驾驶的核心是,强化学习已经广泛应用于机器人控制、游戏游戏、计算机视觉、无人驾驶等领域。在异常数据检测领域,面向强化学习的检测与防御技术并没有太多新的进展。因此,通过强化学习进行异常数据检测已成为安全应用领域的重要挑战。已有研究表明,决策中毒攻击可以通过改变训练集中的奖励来改变决策,使训练集中的策略中毒,动作选择错误,最终代理无法达到学习目的。这种攻击对于无人驾驶等安全决策领域的应用来说是非常致命的。
技术实施要素:
基于这种中毒攻击场景,本发明提出了一种面向强化学习的异常数据检测与防御方法。防御方法基于用于异常数据检测的双向生成对抗网络(GAN)。通过比较正常数据样本和观测数据样本的分布,定义正常数据和异常数据,达到异常数据检测的效果。
本发明的技术方案是:
一种面向强化学习的异常数据检测与防御方法,包括以下步骤:
(1)搭建汽车自动驾驶环境,根据汽车自动驾驶环境提供的状态数据,利用深度确定性策略梯度算法(ddpg)进行强化学习,生成驾驶状态数据作为训练样本;
(2)使用训练样本训练一个由生成器和判别器组成的生成对抗网络;
(3)采集行车状态数据,利用训练好的生成器根据当前时刻的行车状态数据生成下一时刻的预测行车状态数据;
(4)使用训练好的判别器判断下一时刻的真实驾驶状态数据和预测的驾驶状态数据是否正常,如果当前时刻的真实驾驶状态数据异常,则预测驾驶状态数据状态数据正常,使用预测行车状态数据 状态数据代替真实行车状态数据。
优选地,使用深度确定性策略梯度算法进行强化学习生成行车状态数据的步骤包括:
利用主网的主策略网络根据当前时刻的驾驶状态数据st生成动作at,并利用主网的主值q网络计算出动作at的奖励值rt ,并结合驾驶状态数据st、当前时刻的动作at、奖励值rt和下一时刻的驾驶状态数据st+1存入缓冲区;
使用目标网络的目标值q网络根据缓冲区的奖励值rt和驾驶状态数据st+1计算累积奖励值r,根据奖励值和累积计算损失函数奖励值,并使用损失函数更新主值q网络参数;
根据参数更新后主值q网络计算的动作at更新值和主策略网络产生的动作变化值,计算累积奖励函数的梯度,利用梯度更新主策略网络参数;
根据主策略网络参数和主值q网络参数,通过软更新方法更新目标策略网络参数和目标值q网络参数。
优选地,生成器用于根据当前时刻的驾驶状态数据生成下一时刻的预测驾驶状态数据,生成器包括:生成器网络模型采用3层卷积神经网络结构为一个隐藏层,隐藏层使用Batch normalization,激活函数使用relu,最后一层使用tanh激活函数,生成模型优化器使用adam优化器。
优选地,判别器为二分类判别器,用于区分下一时刻预测的驾驶状态数据和下一时刻真实驾驶状态数据的真实性。
在step(4)中,如果判别器的输出表明它来自真实的驾驶状态数据,则表明预测的驾驶状态数据与真实的驾驶状态数据相似,而真实的驾驶状态数据有效。

p>
在步骤(4)中,如果判别器的输出表示来自生成器输出的预测驾驶状态数据,则表示预测驾驶状态数据与真实驾驶状态数据不同,则认为真实驾驶状态数据如果与之前预测的驾驶状态数据分布分离,则将真实驾驶状态数据视为异常数据点,用预测驾驶状态数据代替真实驾驶状态数据。
与现有技术相比,本发明具有以下有益效果:
可以通过GAN网络检测正常状态数据样本的分布;在强化学习过程中,经过训练的GAN网络可用于为当前状态数据生成下一时刻的预测驾驶状态数据。真实驾驶状态数据的分布类似,用下一时刻观察到的真实驾驶状态数据来判断观察到的数据是否异常。这个过程可以在训练过程中实现,异常状态数据可以及时替换。实现对异常数据检测的防御。
图纸说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面简要介绍描述实施例或现有技术中需要用到的附图。显然,以下描述的附图只是本发明的一些实施例,对于本领域普通技术人员来说,在没有创造性劳动前提下,还可以根据这些附图获得其他的附图。
图。附图说明图1是本发明实施例提供的一种面向强化学习的异常数据检测与防御方法的流程图;
图。图2为本发明实施例提供的GAN网络的工作示意图;
图。图3为本发明实施例提供的使用训练好的GAN网络进行异常数据检测与防御的流程图;
图。图4为本发明实施例提供的一种深度确定性策略梯度算法的结构示意图。
具体实现方法
为使本发明的目的、技术方案和优点更加清楚,下面结合附图和实施例对本发明作进一步详细说明。应当理解,此处所描述的具体实施例仅用于解释本发明,并不用于限定本发明的保护范围。
参见图1至图4,本实施例提供的一种面向强化学习的异常数据检测与防御方法,包括以下步骤:
s101,搭建汽车自动驾驶环境,根据汽车自动驾驶环境提供的状态数据,使用深度确定性策略梯度算法进行强化学习,生成驾驶状态数据作为训练样本。
搭建强化学习汽车自动驾驶仿真环境;基于强化学习中的深度确定性决策梯度算法(ddpg)训练汽车玩家。玩家的目标是尽可能快速安全地到达目的地。
在训练过程中,状态转换过程(状态、动作、奖励、下一个状态)作为训练数据集存储在经验回放缓冲区d中; n个训练数据集从d中采样,通过最小化实际累积奖励函数和动作值q函数之间的损失函数来更新主网络的主值q网络的网络参数;通过计算动作值函数的梯度来更新主网络的主策略网络的策略参数;通过软更新方式更新目标网络参数。
强化学习中ddpg算法的核心是基于actor-critic方法、dqn算法和确定性策略梯度(dpg)。其中 at 表示时间 t 的选定动作,st 表示时间 t 的状态,θμ 是生成确定性动作的策略网络 μ(s, θμ) 的参数,μ(s) 充当参与者,θq 是值 q 网络 q(s, a, θq) 的参数充当 q(s, a) 函数的批评者。为了提高训练稳定性,策略网络和价值网络同时引入目标网络。算法步骤如下:
(a) 根据当前策略和探索噪声nt(高斯分布)选择动作at=μ(st|θμ)+nt,执行动作at后,获得奖励rt和下一个状态st+1,并将状态Process(st,at,rt,st+1)存储在体验播放缓冲区d中;
(b) 从d中采样n个状态转移过程(si, ai, ri, si + 1)的小批量,通过最小化损失函数来更新价值网络中的参数θq:
其中yi=ri+γq′(si+1,μ′(si+1|θμ′)|θq′),qμ(si,ai)=e[r(si,ai)+γqμ(si+1 ,μ(si+1))],γ为衰减因子,取值在[0, 1]之间。
(c) 通过计算期望累积奖励函数的梯度来更新策略网络中的策略参数θμ:
(d)通过软更新更新目标值q网络和目标策略网络在目标网络中的参数θq′和θμ′:
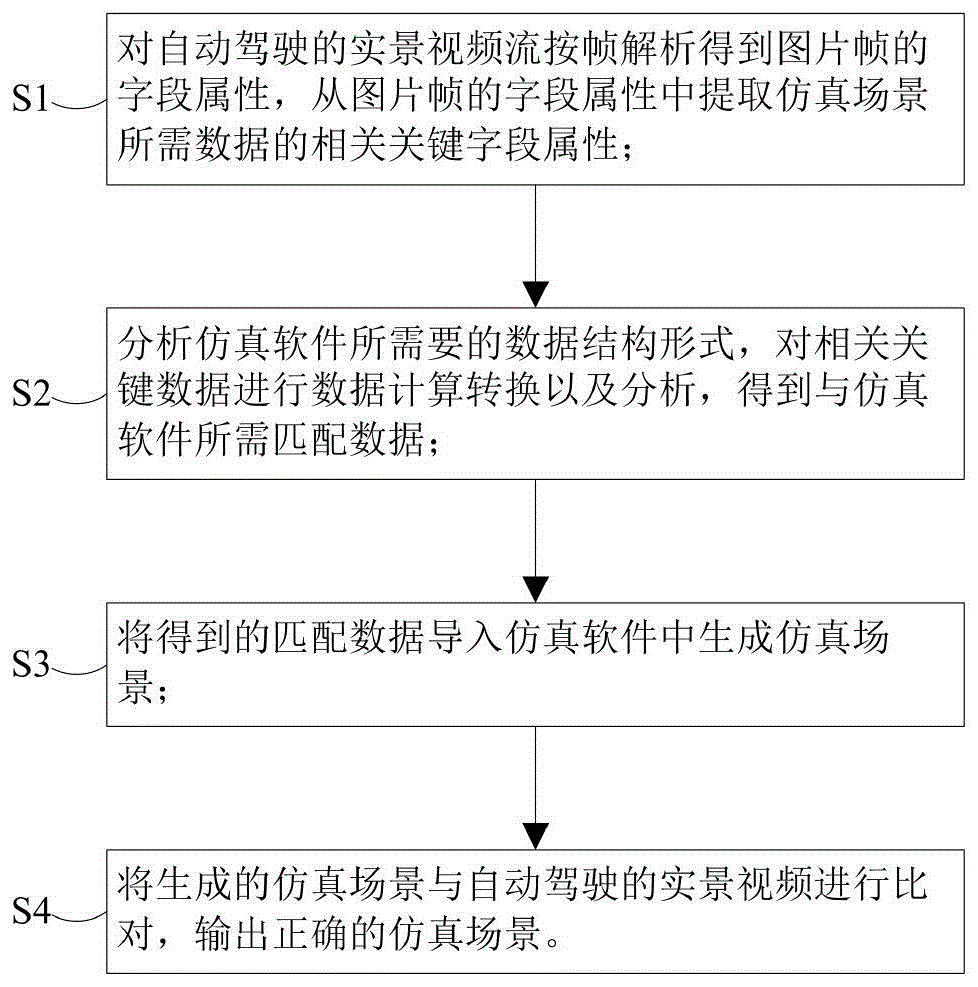
θq′←τθq+(1-τ)θq′
θμ′←τθμ+(1-τ)θμ′
s102,使用训练样本训练一个由生成器和判别器组成的生成对抗网络。
从训练数据集中收集t时刻的正常汽车行驶状态作为样本数据;
gan的目的是使生成的数据和目标数据分布(训练集数据所代表的分布),其中判别器d可以看成是一个二元分类器,用交叉熵表示:
其中minmax表示纳什均衡中的最大最小目标函数,pdata(xs)是来自样本数据的分布,第一项中的logd(x)表示判别器对真实数据的判断,第二项item log(1 -d(x)) 表示对生成数据的判断经过这样一个极大极小博弈过程,循环交替优化g和d,训练出所需的生成网络和判别网络,直到达到纳什平衡点到达。
具体的训练过程是:
2.1)将样本数据按一定比例分为训练集和测试集;
2.2)将训练集中的正常汽车行驶状态数据分布xs输入到生成器g,生成器输出为下一时刻的状态数据x's';
2.3) 将步骤2.2)的输出x′s′和训练集中下一时刻的真实正常状态xs′输入到鉴别器 d;使用判别器的输出y来判断数据来自真实数据的概率,从而检查生成器的输出是否合格;
2.4)重复步骤2.2)-2.3)直到生成器生成的数据样本满足判别器的要求;
2.5)使用测试集中的数据重复步骤2.2)-2.3)以检测生成对抗网络(gan)是否预测状态数据正确生成。
s103、采集行车状态数据,根据当前时刻的行车状态数据,利用训练好的生成器生成下一时刻的预测行车状态数据。使用训练好的判别器判断下一时刻真实驾驶状态数据和预测驾驶状态数据是否正常,当前时刻真实驾驶状态数据是否异常,预测驾驶状态数据是否正常,预测驾驶状态数据用于替换真实的行车状态数据。
具体流程为:
3.1) 数据集中t时刻的状态数据作为生成器的输入,训练好的gan模型输出t+1时刻的预测状态数据该状态数据与之前的正常样本相同。数据分布类似。
3.2) 将 t+1 时刻的预测状态数据和 t+1 时刻强化学习过程中观察到的状态数据输入判别器 d,检查输出 y鉴别器:
如果判别器的输出表明它来自真实状态数据,则表明预测的状态数据与真实状态数据相似,即t+1时刻观察到的状态数据与真实状态数据相似以前的正态样本数据分布,数据有效。
如果判别器的输出表明它来自于生成器的输出数据,则表明预测的状态数据与真实的状态数据不同,即t+1时刻观察到的状态数据是分离的从之前的正态样本数据分布,则将数据作为异常数据点防御性驾驶的核心是,将预测的状态数据存储在训练数据集中,而不是t+1时刻的状态数据;
3.3)重复步骤3.1)3.2),以此类推,继续检测t+2,t+3 ,. ..状态数据一直存在,直到根据策略生成的所有状态数据都被完全检测到为止。
上述在模拟汽车自动驾驶的强化学习训练过程中的异常数据检测防御方法,基于策略中毒的攻击方法会使学习者学习到错误的策略,从而选择一个不好的策略行动,让学习者学会错误。基于这种情况,使用gan来检测数据集中的状态数据是否异常。首先使用正常状态数据训练GAN网络,根据当前状态数据生成下一时刻的预测状态数据,在强化学习过程中与下一时刻的真实状态数据进行判别,检查是否真实数据与之前的正常样本数据一起分布。类似这样来定义数据是否异常。
上述具体实施例对本发明的技术方案和有益效果进行了详细描述。应当理解,上述实施例仅为本发明的最优选实施例而已,并不用于限制本发明。凡在本发明的原则范围内所作的任何修改、增加和等同替换等,均应包含在本发明的保护范围之内。